

Artigo
Artigo
Democratizando a Inteligência Artificial





Não é exagero dizer que a Inteligência Artificial (IA) está em toda parte. A cada momento interagimos com sistemas que fazem uso de IA sem percebermos. Chatbots para atendimento virtual, reconhecimento de imagens, classificação de documentos, segmentação de clientes, definição de crédito e carros autônomos são alguns exemplos de uso dessa tecnologia sexagenária.
Cunhado em 1956 por John McCarthy [1] como "a ciência e engenharia de produzir máquinas inteligentes", a IA é uma área da ciência da computação que busca resolver problemas utilizando métodos inspirados na inteligência humana. Hoje a IA incorpora conceitos (e alguns buzzwords), tais como ciência de dados, aprendizado profundo e aprendizado de máquina, conforme ilustrado na Figura 1. Observe na figura que a inteligência artificial é uma grande área que contempla o aprendizado de máquina e o aprendizado profundo. De forma transversal, temos a ciência de dados que aproxima as necessidades de negócio às técnicas, incorpora as tecnologias que permitem manipular grandes volumes de dados, dentre outros aspectos.
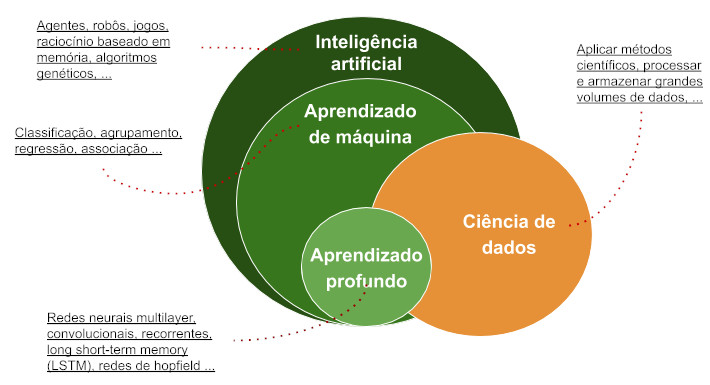
Figura 1 - Relação entre inteligência artificial, aprendizado de máquina, aprendizado profundo e ciência de dados.
Apesar de encontrarmos soluções de IA em diferentes produtos, sua utilização ainda é limitada a especialistas com habilidades e conhecimentos muito específicos. Tipicamente, as soluções são desenvolvidas em linguagens de programação como Python e R ou utilizando ferramentas que abstraem as tarefas de programação utilizando diferentes componentes conectados.
Outra característica inerente aos algoritmos utilizados em IA, que remete a necessidade do especialista, é o ajuste de parâmetros. Os algoritmos demandam ajustes em diferentes parâmetros, os quais influenciam diretamente a qualidade dos resultados. Ademais, os algoritmos são irregulares; i.e., dependentes das características dos dados. Logo, a efetiva utilização das diferentes técnicas e algoritmos disponíveis passa pela compreensão dos mesmos e da influência dos dados e dos parâmetros no comportamento do algoritmo.
Em síntese, os processos de IA são extremamente dependentes do especialista e muitas organizações não possuem uma equipe com esse perfil; seja pela dificuldade em conseguir formar uma equipe com o perfil desejado ou por não ser o foco da organização.
AutoML (automated machine learning)
Com o objetivo de democratizar a IA e disponibilizá-la ao maior número possível de usuários, surgiu o AutoML (automated machine learning) com a proposta de automatizar de ponta a ponta a aplicação de aprendizado de máquina em problemas do mundo real para usuários de negócio ou cientistas de dados. Com pouco conhecimento em IA e nenhuma habilidade em programação é possível um usuário de negócio construir um modelo e apresentar resultados iniciais que validam uma ideia de forma rápida e independente de equipes especializadas. Por outro lado, o AutoML permite aos cientistas de dados explorar diferentes modelos e algoritmos de forma rápida; fornecendo ao profissional um entendimento inicial a respeito do potencial dos dados para resolver o problema de negócio em foco.
Para ilustrar o potencial do AutoML, vamos fazer uso do processo CRISP-DM (cross-industry standard process for data mining) [2], como exemplo. Aplicações reais tipicamente passam pelas etapas de compreensão do negócio, entendimento dos dados, preparação dos dados, modelagem, avaliação e implantação da aplicação de forma cíclica. Na Figura 2, essas etapas, representadas no processo CRISP-DM, são apresentadas com destaque para as etapas automatizadas, em algum grau, por meio das técnicas de AutoML.
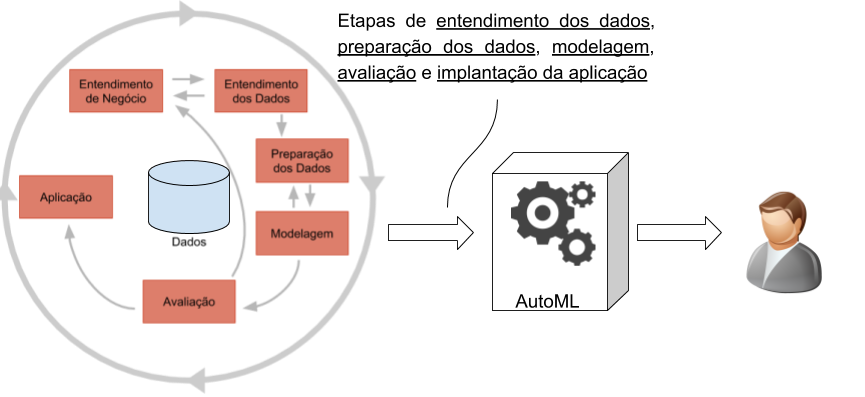
Figura 2 - Processo CRISP-DM e as etapas automatizadas, em algum grau, por meio das técnicas de AutoML.
As soluções de AutoML automatizam e facilitam a construção de sistemas de diferentes formas:
- Entendimento dos dados - procura detectar o tipo de cada registro (texto, booleano, numérico ou discreto) e permite ao usuário facilmente visualizar informações sumarizadas a respeito dos atributos que representam o domínio do problema. Por exemplo, valores mínimo, máximo, média e desvio padrão. Diferentes tipos de gráficos e formatos de visualização dos dados são apresentados ao usuário de forma fácil e bastante intuitiva.
- Preparação dos dados - automaticamente procura detectar o objetivo de cada atributo (atributo alvo ou preditor). Informações sobre dados ausentes ou valores discrepantes são comumente informados pelas soluções de AutoML. Uma vez identificadas características como dados ausentes são apresentadas soluções para o usuário escolher. Algumas possibilidades são remover os registros que possuem dados ausentes, atribuir um valor fixo como a média ou prever o valor com base nos demais atributos. Ademais, os atributos mais relevantes para o domínio do problema são selecionados utilizando técnicas de feature selection. Por último, a identificação das possíveis tarefas alvo, aplicáveis a base de dados, são apresentadas: classificação, regressão, clusterização etc.
- Modelagem - selecionada a tarefa alvo, diferentes modelos são aplicados e para cada modelo diferentes algoritmos. Por exemplo, definido uma tarefa de classificação pode-se aplicar um modelo baseado em árvore de decisão, rede neural, vizinho mais próximo (KNN) etc. No modelo baseado em árvore aplicar os algoritmos C4.5, CART, dentre outros. Em cada algoritmo, diferentes parâmetros de configuração são explorados de forma transparente para o usuário final.
- Avaliação - as diferentes modelagens exploradas são avaliadas utilizando alguma métrica. Por exemplo, acurácia, precisão, recall, F1 score etc. Ao final do processo, o modelo e algoritmo com melhores resultados são selecionados de forma automática.
- Aplicação (implantação) - o modelo construído é publicado para consumo tipicamente como uma API REST.
Atualmente encontramos diferentes propostas de AutoML. Comercialmente são observadas soluções que contemplam várias atividades das etapas do processo CRISP-DM. No formato open source temos soluções que atuam em atividades específicas, por exemplo, na escolha do melhor algoritmo para uma tarefa de classificação utilizando Python [3][4]. Ademais, são observadas propostas independentes de programação com o Auto-Weka [5].
Em síntese, podemos sumarizar as principais vantagens do AutoML em alguns pontos:
- Democratiza funcionalidades da inteligência artificial, aprendizado de máquina, aprendizado profundo e ciência de dados;
- Aumenta a produtividade automatizando tarefas;
- Evita erros que podem ser criados em tarefas manuais;
- Permite construir soluções simples e rápidas;
- Gera modelos que superam, em alguns casos, modelos construídos a mão;
- Permite aos profissionais manter o foco no negócio;
- Reduz a latência entre os dados e a tomada de decisão.
Conclusões
Naturalmente, a inteligência artificial será cada vez mais comum entre os usuários e é notório que sua democratização passa pela adoção de soluções como o AutoML; i.e., soluções que abstraem os aspectos computacionais e tornam o uso da tecnologia transparente para o usuário final. Aqui, podemos fazer um paralelo histórico com uso de planilhas. Quando propostas no final da década de 70, as planilhas eram restritas a grupos específicos de profissionais (contadores, profissionais de informática etc). Hoje é uma ferramenta comum, utilizada naturalmente por qualquer usuário.
Para conhecer mais sobre métodos, metodologias e desafios do AutoML consulte a referência [6].
Referências
[1] History of artificial intelligence - https://en.wikipedia.org/wiki/History_of_artificial_intelligence <último acesso em Outubro de 2019>
[2] CRISP-DM - https://en.wikipedia.org/wiki/Cross-industry_standard_process_for_data_mining <último acesso em Outubro de 2019>
[3] Auto-sklearn - https://automl.github.io/auto-sklearn/master/ <último acesso em Outubro de 2019>
[4] TPOT - https://github.com/EpistasisLab/tpot <último acesso em Outubro de 2019>
[5] Auto-Weka - https://github.com/dsibournemouth/autoweka <último acesso em Outubro de 2019>
[6] Hutter, Frank, Lars Kotthoff, and Joaquin Vanschoren. "Automated Machine Learning-Methods, Systems, Challenges." Automated Machine Learning (2019). https://doi.org/10.1007/978-3-030-05318-5
Autor:
 Sérgio M. Dias é Doutor e Mestre em Ciência da Computação pela Universidade Federal de Minas Gerais (UFMG) (2016 e 2010) e Bacharel em Ciência da Computação pela Pontifícia Universidade Católica de Minas Gerais (PUC Minas) (2007). Em 2017, realizou um pós-doutorado no tema ciência de dados na PUC Minas. Atualmente, é analista na Superintendência de Soluções Analíticas de Inteligência Artificial (Supai) e professor na pós-graduação da PUC Minas. Nos últimos 10 anos, atuou no Serpro em projetos estratégicos, tais como: Nota Fiscal Eletrônica, Escrituração Fiscal, E-social e Data Lake. Home page: www.sergiomdias.com
Sérgio M. Dias é Doutor e Mestre em Ciência da Computação pela Universidade Federal de Minas Gerais (UFMG) (2016 e 2010) e Bacharel em Ciência da Computação pela Pontifícia Universidade Católica de Minas Gerais (PUC Minas) (2007). Em 2017, realizou um pós-doutorado no tema ciência de dados na PUC Minas. Atualmente, é analista na Superintendência de Soluções Analíticas de Inteligência Artificial (Supai) e professor na pós-graduação da PUC Minas. Nos últimos 10 anos, atuou no Serpro em projetos estratégicos, tais como: Nota Fiscal Eletrônica, Escrituração Fiscal, E-social e Data Lake. Home page: www.sergiomdias.com